Benchspan
Real-Time Security for AI Agents in Production
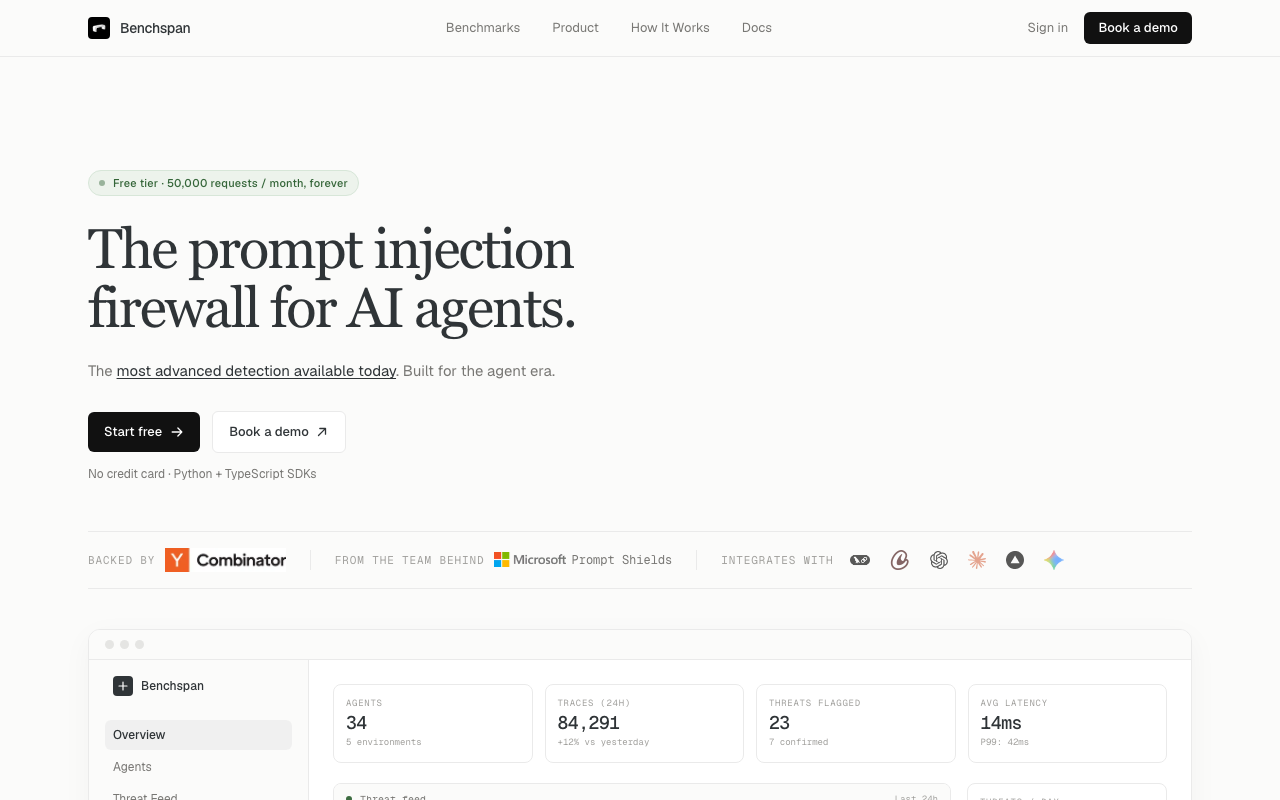
Our Take
Benchspan is low-key solving the AI security problem everyone else is ignoring — indirect prompt injection, where attacks hide inside the documents, emails, and tool outputs that agents actually read while working. Their detector specifically trained for this (not generic prompt injection) nailed a 99.9% catch rate on AgentDojo versus 71% for the next best commercial option, and they've already flagged 23 threats with 7 confirmed across 34 monitored agents, which is the kind of traction that makes platform companies pay attention. The 14ms average latency means it actually works inline without turning your agent pipeline into a mess, and the compliance reporting covers EU AI Act and NIST AI RMF for the enterprise crowd, which is the move if you're selling to agent platform teams in 2026.
A custom security model built for AI agents that stops attacks your guardrails miss. It sits on the request path and evaluates every LLM call, tool invocation, and RAG retrieval in real-time.
Key Facts
The people behind Benchspan
Links
Want products like this in your inbox every morning?
Five products. Every morning. Written by someone who actually cares whether they're good or not. Free forever, unsubscribe whenever.